
https://www.sciencedirect.com/science/article/pii/S0167865520302221
会議はPattern Recognition LettersというJournal。
Introduction
Unsupervised Domain Adaptationでは、LabeledのソースとUnlabeledのソースは異なるという設定が普通。
については言及なし。
だが最近はOpen Set Domain Adaptationというソースとターゲットデータがどちらも含まれているクラスと、片方のドメインにしかないクラスが存在する設定が主流。
外れ値検出などについてちゃんと考えるべき。
ここに、PU Learningを導入する。異常検知とかはPUでできるわけだし。
この研究では、ソースドメインにあるサンプルをP,ターゲットドメインにあるサンプルをUとみなす。Negative Transferという過度にNegativeに傾く問題も解消したという。貢献は以下の通り
- nnPUをベースに、ドメイン間の相違のロバスト性を考慮した損失関数を開発。
- Domain Adversarial Learningというのを取り込み、Negative Transferを防ぐように頑張った。
Related Works
Domain Adaptation
Domain Adaptationについては、このSurveyを見るといい。📄![]() 2021-Survey-A Comprehensive Survey on Transfer Learning (Part1) Instance Weighting Strategy
2021-Survey-A Comprehensive Survey on Transfer Learning (Part1) Instance Weighting Strategy
分布の距離を最小化するように変換する、Domain DiscriminatorがどっちのDomainのデータなのかを識別できなくなるように敵対的な訓練を行うなどがある。
分類器はソースとターゲットの間を大きく離すように学習され、2つ目の研究は既知クラスと道クラスのサンプルを分離して特徴分布のアライメントに重要度で重みづけしているらしい。これが今までのOpen Set Domain Adaptation。
Open Set Recognition
未知のクラスの存在を加味した学習をする必要がある。浅い層での学習でカスタマイズされたSVMやkNNを使われていたらしい。training dataをaugmentしたりしてるらしい?
外れ値検出
1クラスSVMによる検出がよくある。最近は正常値で学習されたモデルは外れ値に弱いとわかった。オートエンコーダーや、GANで正常値の分布する多様体の学習をしたりなどがある。
PU Learningの説明は略す。
問題設定
- Ground Truthのラベルは^
- Class Priorは
- 問題設定はCase Control。
使うのは、uPU 📄![]() 2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data の式
2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data の式
これについて、表現力が高い負の項が過学習しないようにclipしたり、Gradient AscendをしたのがnnPU 📄![]() 2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator である。
2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator である。
Autoencoder-based Classification Loss And nnPU risk
nnPUの損失関数は、深層学習の時はよくlog損失を使う。
しかしこのままではPとUが異なるDomainから選ばれている状況には対応できない。
ここでDomain Adaptationを行うが、典型的な手法として敵対的な識別によるDomain Adaptationをやりたい(識別器がどのDomainからきているかを識別できなければ十分にDomain間をマッチできているといえる)。やり方はいろいろあるが、今回はAutoEncoderをつかう。
Encoderを使うことで、低次元の特徴を抽出でき、それがDomainが違くとも共通の特徴であることを期待している。そして、で高次元にほぼ復元できるようにしたい。
いろいろ使うのはでそれを訓練するためにDecoderがついている感じ。
エネルギーベースの識別器は多様体の近くの領域に低エネルギー、それ以外は高エネルギーを割り当てている。ドメイン間に亘る低次元特徴は多様体の上にあるという仮説に従うんで。
これらを踏まえて、損失関数をEncoder ,Decoderを導入したかたちで再定義する。
つまり、
- Encoder, Decoderを通してPositiveのものはそのまま復元できるようにしたい。
- Negativeは下述のようにという定数へのマッピングをするので、ちゃんとPositiveとの差は大きくなるようにしたい。
- Negativeのものは、ハイパラがすべての成分となるのベクトルに近づくようにしたい。
- 入力のに一切依存せずに同じ定数のベクトルへのマッピングをする。これによって、PositiveとNegativeの区別をしやすくするため。
これを踏まえて、nnPUの式は以下の目的関数になる。
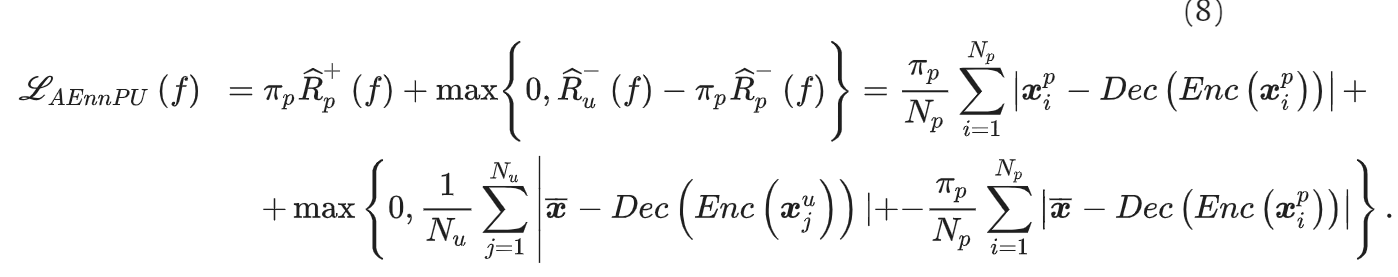
ラベルの決定については、ある閾値が存在し、である。
の決定はいつも通り、top-kのようにする。
Open-set Domain Adaptation as a PU Problem
Open-set Domain Adaptationでは、Sourceはがあり、Targetはがある。Source Domainにあるクラスよりも真に多いクラスをTarget Domainは含んでいる。例えばSourceには数字0-4のクラスがあるが、Target Domainには数字0-9がある。
このような状況で、共通でもつクラス0-4であるか、Target Domainにしか出現しないクラスかを識別するのがOpen-set Domain Adaptationのやりたいこと。
ここでSource DataをP、Target DataをUとみなせば、確かにPU Learningの形になる。SCARではない上、同じPの中でも所属するクラス(0-4のどれか)を明らかにする必要があるので、以下のような構造になる。
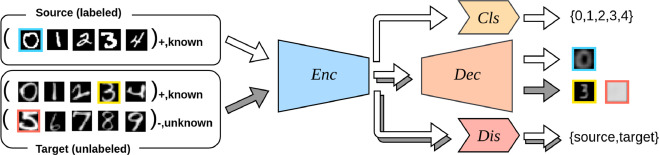
- Clsは中間表現を用いて、既知のクラスのうちのどれであるかを識別する。
- DecはPUREのnnPUの式の最小化に使う。
- Disは敵対式識別器で、識別の損失が大きいほうが(うまくEncoderをhackし、Domain依存の特徴を見つけられたので)うれしい。
- 敵対的な訓練でよくある。
- 実際には、Disを固定して、Encoderを訓練→Encoderを固定してDis、Decoder,Classifierを訓練のように交互に訓練する。

Experiment
MNIST, MNIST-M, USPS, SVHN(実際のストリートビューの画像)。10クラスのデータセットなので、最初の5個はSource, Target両方に含まれていて、残りの5クラスはTarget Domainにのみ存在すると考える。
CIFAR10, STL-10も同様に使った。Office-31では最初の0-9のクラスは共有、最後の10クラスはTarget Domainで未知らしい(謎)
評価基準は既知クラスの平均精度と、未知のクラスの判定の精度の調和平均。
Result
PUREは選択バイアス(Uの中のP/N比を変更する)があっても、十分にロバストである。を与えずに推定させる形でも、これはうまくいった。
なので、この手法は非常に良い。